Im März hat Google Scholar die Funktion „Public access“ in Google-Scholar-Profilen integriert. Anliegen ist es, so Google, Forschende bei der Umsetzung von Open-Access-Policies („public access mandates“) zu unterstützen.
In Google Scholar sind nun die Open-Access-Policies von 182 Förderorganisationen und wissenschaftlichen Einrichtungen hinterlegt (Stand: 09.04.2021). Aus Deutschland u. a. die Open-Access-Policies der Deutschen Forschungsgemeinschaft (DFG), der Fraunhofer-Gesellschaft, der Helmholtz-Gemeinschaft und der Leibniz-Gemeinschaft.
Wie so oft bei Google Scholar ist das Verfahren eine Blackbox, d.h. wir können nur vermuten wie Google die „Public access“-Funktion im Detail umsetzt. Ein lesenswertes Interview hierzu mit Anurag Acharya, einem der Köpfe hinter Google Scholar, findet sich in Nature.
In diesem Interview wird der Ansatz der „Public access“-Funktion deutlich: Automatisiert werden die „Funding Acknowledgements“ in Papers mit den Policy-Informationen abgeglichen. Ist ein Artikel nicht frei im Web auffindbar, erscheint ein Hinweis in der „Public access“-Sektion in dem Google-Scholar einer/eines Autor*in. Die Auffindbarkeit bezieht sich dabei nicht nur auf Open-Access-Repositorien und Verlagsportale, sondern auf jegliche von Google indexierte Verzeichnisse im Web.
Offenbar wurde die Funktion langsam ausgerollt. Seit einigen Tagen findet sich die Funktion auch in dem Back-End meines Google-Scholar-Profils. Folgender Screenshot zeigt die „Public access“-Funktion in meinem Profil:

Per Klick auf die Funktion landet man auf einer Webseite, die Artikel listet, die laut Google Scholar durch eine Open-Access-Policy tangiert sind. In meinem Fall sind dies, so Google, 14 Veröffentlichungen. Zu jeder der Publikationen wird eine Leit- oder Richtlinie („Mandate“) angezeigt (siehe Screenshot).
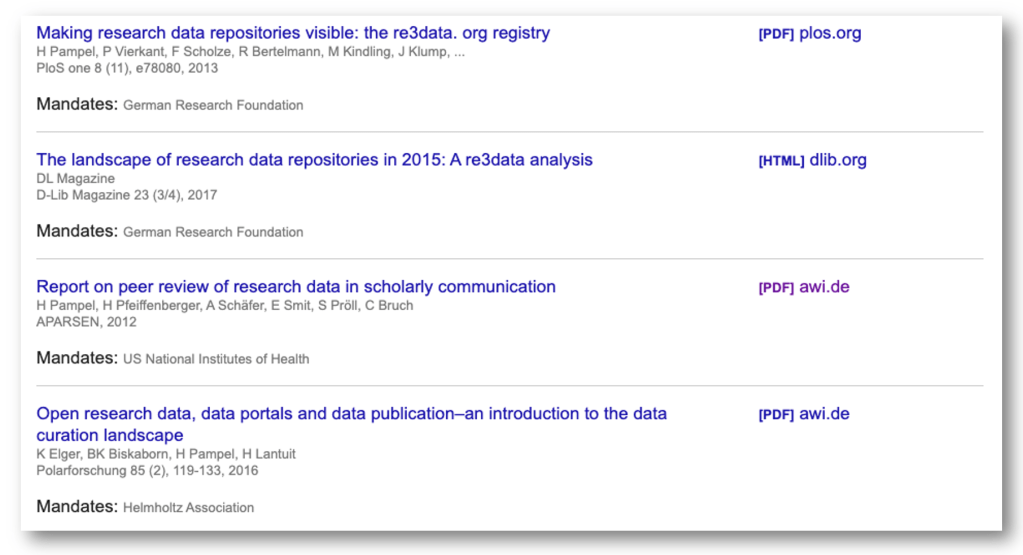
In meinem Fall waren bereits alle von Google identifizierten Publikationen frei zugänglich. Die Auswahl der 14 Paper und ihre Zuordnung zu den Open-Access-Policies überrascht jedoch und zeigt die Schwäche der neuen Funktion. Der automatisierte Abgleich der Angaben zu den Förderorganisationen und wissenschaftlichen Einrichtungen scheint wenig verlässlich. So erscheint in meiner Liste z. B. dreimal die National Institutes of Health (NIH) als Förderorganisation, obwohl ich bisher noch nie in einem von den NIH geförderten Projekt involviert war. Auch kann ich die Auswahl der 14 Paper nicht nachvollziehen. Somit scheint weder die Zuordnung noch die Auswahl verlässlich.
Zu hoffen ist, dass sich solche Fehler, die bei sprachbasierten Verfahren wenig überraschend sind, in Zukunft durch das Research Organization Registry (ROR) und dessen persistenten Identifikator für wissenschaftliche Einrichtungen und Förderorganisationen erledigen. (Siehe dazu unsere Arbeiten im ORCID-DE-Projekt.)
Auch irritiert es, das Google statt dem weltweit gebräuchlichen Term „Open Access“ den Begriff „Public access“ verwendet. Dieser ist zwar in den USA durch eine Verordnung der US-Regierung zu Open Access aus dem Jahr 2013 gängig, aber international kaum verbreitet.
Mehrere Kolleg*innen weisen kritisch darauf hin, dass Google Scholar, im Falle eines nicht frei zugänglichen Artikels, seine Dienst Google Drive als Alternative zu Open-Access-Repositorien bewirbt. Diesem Hinweis von Google sollte man besser nicht folgen und sich anstelle an seine lokale Bibliothek wenden. Die Bibliothekar*in wird sicher ein passendes Repositorium empfehlen können und eine/einen Autor*in im Idealfall auch gleich bei der Rechteprüfung unterstützen.
Die Google-Scholar-Funktion kann dazu beitragen wissenschaftliche Autor*innen für Open Access zu sensibilisieren, auch wenn die Angaben von Google Scholar nur bedingt belastbar scheinen. Auch zeigt die Funktion, dass die Relevanz der Compliance von Open-Access-Förderbedingungen steigt. Hierzu passt auch der Einstieg von Förderorganisationen in das Verlagswesen, wie es jüngst die Europäische Kommission mit ihrer Open-Access-Zeitschrift „Open Research Europe (ORE)“ tat. Die Europäische Kommission stellt mir ORE eine Plan-S-konforme Publikationsplattform bereit. Die Zeitschrift richtet sich an Forschende, die Ergebnisse aus EU-geförderten Projekten publizieren.



 Passend zum Thema Metriken für Open Science hat heute die „Expert Group on Altmetrics“, die die Generaldirektion Forschung und Innovation der EU-Kommission berät, ihren
Passend zum Thema Metriken für Open Science hat heute die „Expert Group on Altmetrics“, die die Generaldirektion Forschung und Innovation der EU-Kommission berät, ihren 