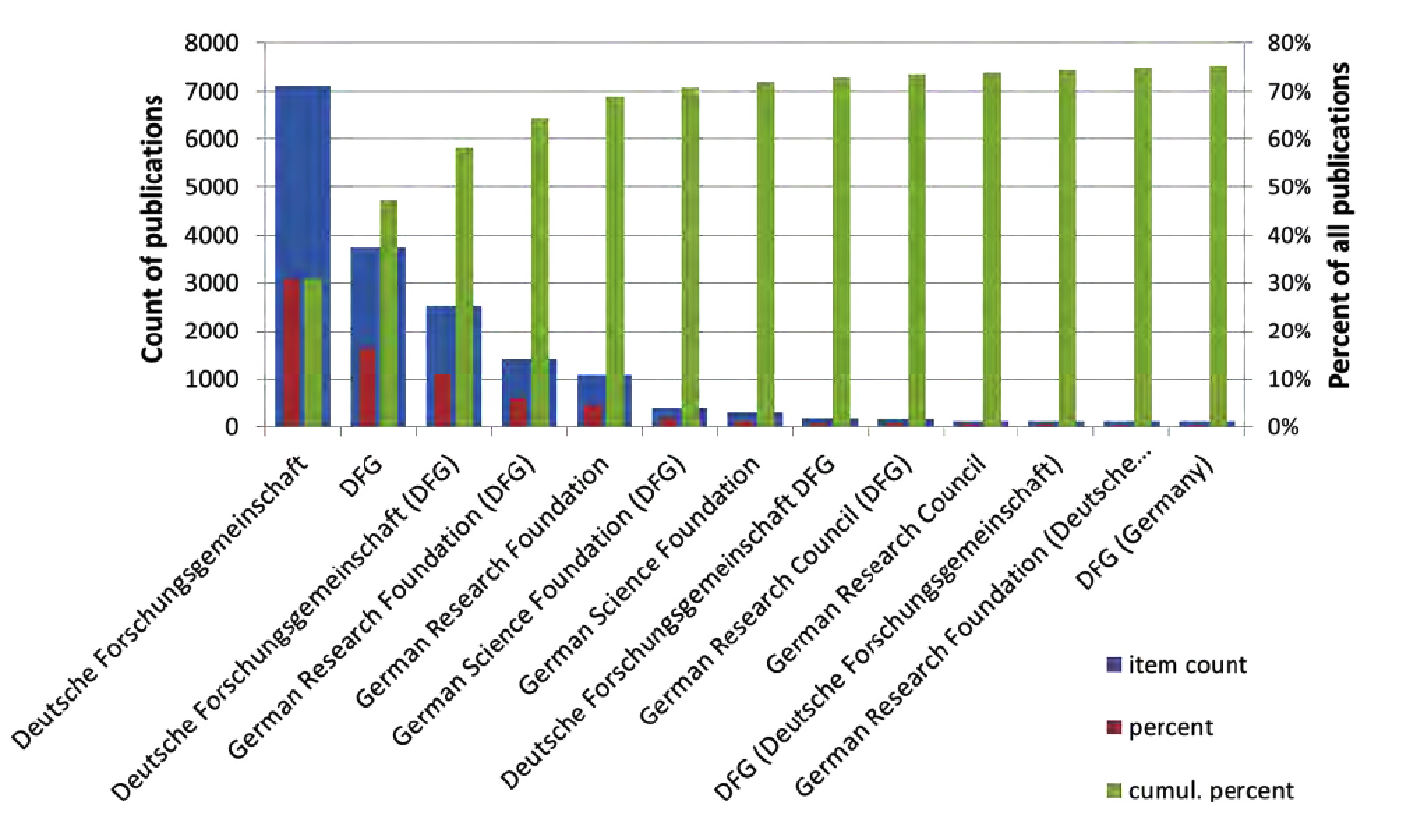
Crossref wurde im Januar 2000 von einer Gruppe der grossen Verlage (AAAS, AIP, ACM, Elsevier, IEEE, Springer, Kluwer, NPG, OUP, Wiley) mit folgenden Ziel gegründet:
To promote the development and cooperative use of new and innovative technologies to speed and facilitate scientific and other scholarly research.
Was als Initiative eines kleinen Club der „Reichen und Grossen“ angefangen hat, ist nun 20 Jahren danach eine international relevante Infrastruktur mit mittlerweile über 12’000 Mitglieder. Insbesondere durch das Sponsoring, bei dem eine (meist nationale) Institution die Mitgliedschaft für kleine Verlage sponsert, erfährt Crossref einen ungebrochenen Zuwachs von über 150 Mitgliedern monatlich.

Finanzierung
Die Finanzierung von Crossref besteht hauptsächlich aus zwei Komponenten:
a) 40% aus einem Mitgliederbeitrag der gemäss Umsatz eines Mitglieds festgesetzt wird.
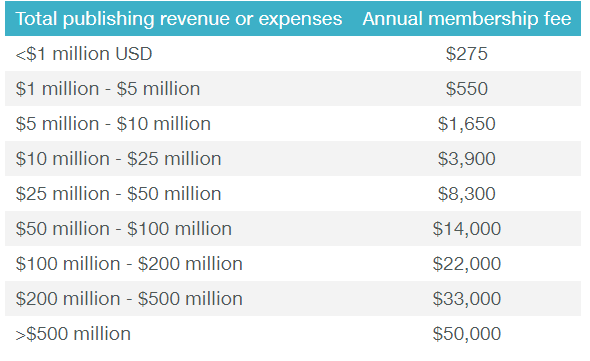
b) 60% aus einer Gebühr die für jede Registration eines DOI fällig wird:

Die Mitgliederbeiträge der 11’799 kleinen Mitglieder (Umsatz kleiner als USD 1m) übertreffen inzwischen die Mitgliederbeiträge der 353 grösseren Mitglieder (Umsatz grösser als USD 1m). Letztere registrieren jedoch 3 mal mehr DOIs als a kleinen Verlage zusammen, und zahlen insgesamt dann doch mehr an Crossref ein.
Governance
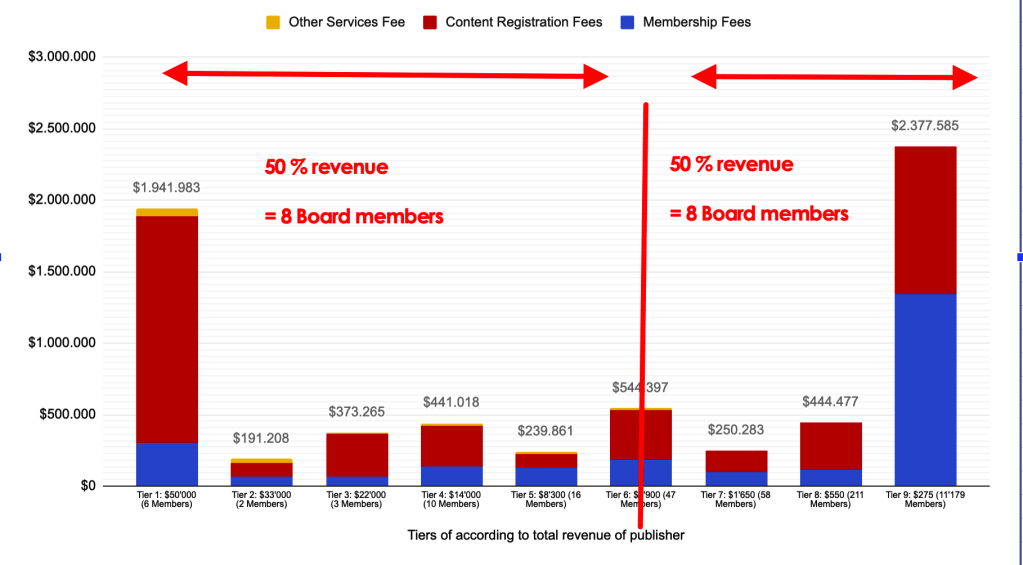
Das Board von Crossref besteht aus 16 Personen. Die Statuten sehen vor, dass jeweils die Hälfte des Boards durch Mitglieder aus den Tiers besetzt werden, die 50% des Budgets von Crossref beisteuern. Durch den starken Zuwachs bei kleinen Verlagen in den letzten 8 Jahren hat sich somit auch das Stärkeverhältnis im Board zugunsten der kleineren Verlage verschoben.
Unzufriedenheit bei einigen Grossen
2014 wurde die Mission überarbeitet und lautet seither:
Crossref makes research outputs easy to find, cite, link, assess, and reuse.
We’re a not-for-profit membership organization that exists to make scholarly communications better. We rally the community; tag and share metadata; run an open infrastructure; play with technology; and make tools and services—all to help put scholarly content in context.
It’s as simple—and as complicated—as that.
Eine zum 20-jährigen Bestehen von Crossref durchgeführte Umfrage zeigt nun, dass insbesondere ein paar grosse Verlage mit der aktuellen Ausrichtung von Crossref auf eine breitere Community ihre Mühe haben, und sich eine Rückbesinnung das Ursprüngliche wünschen. Zwei grosse Verlage haben gar erwähnt Crossref womöglich zu verlassen und andere persistente IDs zu verwenden.

Powell, J. (2019). Crossref Value and Benefits, slide 25 
Powell, J. (2019). Crossref Value and Benefits, slide 35 
Powell, J. (2019). Crossref Value and Benefits, slide 37 
Powell, J. (2019). Crossref Value and Benefits, slide 46
Crossref Meeting: Have your say
Beim jährlichen Meeting von Crossref LIVE19 in Amsterdam stand denn auch die aktuelle Ausrichtung von Crossref auf dem Prüfstand durch die Mitglieder und der Community. Am ersten Tag wurden die Umfrageergebnisse präsentiert und es gab kurze Präsentation wie die Community (Grosser, mittlerer, kleiner Verlag, Förderorganisation, Universität) Crossref sieht. Am zweiten Tag wurde anhand des ausgeteilten Annual Report & Fact File an mehreren zugewiesenen Tischen die Fakten und Strategie vergegenwärtig und Input für die Zukunft gesucht.
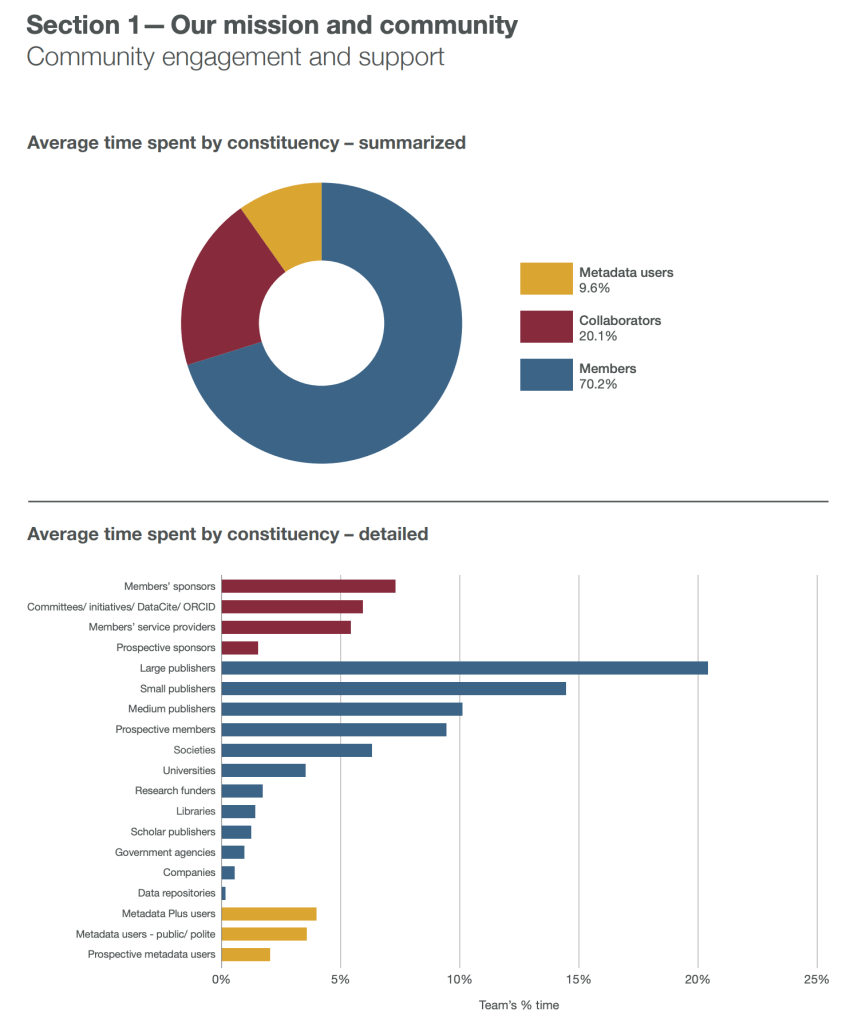
Im Factsheet (p.11) zeigte Crossref beispielsweise auf, in welchen Bereichen aktuell Zeit aufgewendet wird, verbunden mit der Frage ob diese Verteilung angemessen sei?
Oder es wurde anhand der strategischen Roadmap darüber diskutiert, ob nun den Ausbau von Event Data, der Abbau von technischen Schulden oder eine gemeinsame Suche mit DataCite wichtiger wäre.

Auch wenn die Resultate dieser Diskussionen natürlich nicht repräsentativ als Handlungsanweisung für Crossref gelten können, hat es den Anwesenden doch geholfen, zu sehen wo Crossref aktuell überall engagiert ist und inzwischen eben weit mehr ist als nur eine DOI-Registrationsagentur.
Wie offen soll Crossref sein?
Crossref ist hinsichtlich dem Geschäftsmodell (Closed- oder Open Access) seiner Mitglieder agnostisch und hat bisher eigentlich sehr gut als neutrales Bindungsglied funktioniert. Es stellt sich die Frage, ob das wirklich so bleiben kann. Gerade wenn es um Vollständigkeit von Metadaten (z.B. Abstracts, Referenzen (I4OC)) oder um TextMining geht, verhindert das alte Geschäftsmodell von einigen traditionellen Verlagen die Innovation bei Crossref und den Nutzen für die breitere Community.
Offene und vollständige Metadaten bei Crossref ermöglicht Dritten mit geringen Hürden neue Dienste darauf aufzubauen und ggf. auch kommerziell zu vermarkten. Siehe beispielsweise die Vision von Jason Priem (Gründer von unpaywall):
Dies birgt natürlich Interessenskonflikte mit denjenigen Crossref Mitgliedern, welche im Analytics-Bereich bereits Produkte haben, oder sich dorthin bewegen wollen. Siehe dazu auch die SPARC Landscape Analysis, welche anhand von Elsevier, Wiley und SpringerNature diesen Wechsel aufzeigen.
Bei Meeting in Amsterdam, verwies Ed Pentz, langjähriger Direktor von Crossref völlig zurecht auf das folgende Zitat von Amy Brand (Direktorin MIT Press) aus dem Blog Post: Crossref at a Crossroad:
The Crossref of 2040 could be an even more robust, inclusive, and innovative consortium to create and sustain core infrastructures for sharing, preserving, and evaluating research information. [But only if Crossref is not] held back, and its remit circumscribed, by legacy priorities and forces within the industry that may perceive open data and infrastructure as a threat to their own evolving business interests.
Ich kann mich dem vollständig anschliessen. Gerade wenn nun Förderorganisationen anfangen für Grants bei Crossref DOIs zu registrieren, muss die Priorität weiter auf „Open“ gesetzt werden. Am besten aber so, dass das verbindende Element von Crossref weiterhin zum Tragen kommt.