Ein DOI ist ein eindeutiger Identifier und eine URL, die zum wissenschaftlichen Beitrag führt.
Was viele jedoch nicht wissen, dass hinter einem DOI auch extrem umfangreiche und frei verfügbare Metadaten über den Beitrag stecken (können). Zu diesen Metadaten im JSON-Format gelangt man, wenn man den DOI mit einer anderen URL aufruft:
http://api.crossref.org/works/10.1128/JVI.03123-13
Bibliografische Grunddaten
Hinsichtlich den Metadaten von Artikel, Buchbeiträgen oder Bücher umfasst das Schema die klassischen Angaben, wie Titel, Publikationsdatum, Volume, Issue, Seitenzahlen, Journal, Serientitel, Journal, ISSN, Buchtitel, AutorInnen und Herausgebern.
Bezüglich AutorInnen ermöglich das Schema die Erfassung einer ORCID und einer Affiliation. Anstelle bzw. zusätzlich zur Erfassung der Affiliation als Text dürfte demnächst die ROR ID hinzukommen.

Lizenzangaben
Unter welcher Lizenz ein wissenschaftlicher Beitrag zugänglich ist, kann ebenfalls im Schema ausgegeben werden:
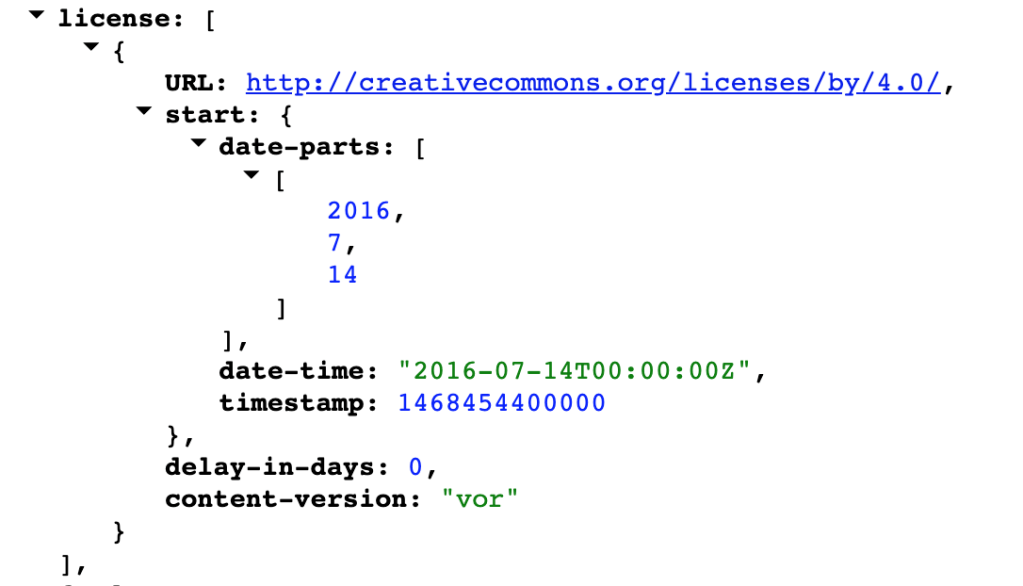
Hinsichtlich Open Access wird überwiegend eine Creative Commons Lizenz ausgegeben. Wie ein Blick auf alle verfügbaren Lizenz-Informationen bei Crossref zeigt, gibt es allerdings auch Verlage die wohl aus Versehen, aber auch aus voller Absicht eine eigene Lizenz vergeben. Unpaywall greift beispielsweise auf diese Information zurück.
Text-Mining
Die meisten DOIs führen zunächst auf eine Landing-Page und erst von dort dann zum eigentlichen Volltext. Für das Text-Mining oder die Archivierung möchte man aber direkt zum Volltext kommen und auch eine Präferenz mitgeben, in welchem Format (HTML, PDF, XML, EPUB) man den Volltext erhalten möchte. Das Crossref-Schema erlaubt dies via dem Element link, wo Verlage die direkte URL zum Volltext und dem entsprechenden Format deklarieren können.

Funding-Information
Die Typischen Informationen des „Funding Acknowledgments“ können strukturiert bei Crossref ausgegeben werden:

Einige Verlage wie z.B. MDPI lassen die AutorInnen diese Information strukturiert erfassen, andere extrahieren diese Informationen vom Paper mittels Text-Mining. Für die Identifikation der Förderorganisationen, wird eine von Crossref gepflegte Liste von 21k Organisationen verwendet. Es gibt zurzeit Bestrebungen, dass Förderorganisationen für Grants ebenfalls einen DOI bei Crossref registrieren, und somit eine solidere Verknüpfung von Publikationen zu Grants möglich ist.
Zitationen / Referenzen
Die verwendete Literatur bzw. die verwendeten bibliografischen Quellen können bei Crossref registriert werden. Im Idealfall passiert das strukturiert mittels Verweis auf einen anderen DOI:

Aber auch wenn kein DOI existiert kann die Referenz ausgegeben werden:

Crossref berechnet dann für Angabe die Anzahl Zitationen innerhalb des Crossref-Korpus.
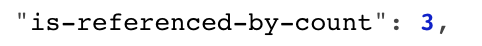
Welche Publikationen sich hinter dieser Anzahl verstecken ist (bislang) via Crossref direkt nur für den Verlag einsehbar, welcher den DOI registriert hat. Dennoch können Dritte, wie OpenCitations die Metadaten aller DOIs nutzen um einen offenen Index mit Zitation zu erstellen. Die „Initiative for Open Citations“ (I4OC) versucht Verlage zu überzeugen ihre Zitationsdaten bei Crossref verfügbar zu machen.
DOIs für Peer Reviews
Seit 2017 ermöglicht Crossref auch die separate Vergabe von DOIs für Artefakte des Peer Reviews (z.B. referee reports, decision letters, and author responses). In den Metadaten der Publikation wird dann auf diese Artifakte verwiesen.

Weitere DOI Agenturen: DataCite, mEDRA
Nun ist Crossref nicht die einzige Organisation die DOIs vergibt. Aktuell gibt es noch 7 weitere Agenturen, welche beispielsweise auch DOIs für Filme vergeben (z.B. Harry Potter). Um zu sehen, bei welcher Agentur ein DOI registriert ist, kann man auch die API von Crossref nutzen:
https://api.crossref.org/works/10.19218/3906897011/agency
Aus meiner persönlichen Erfahrung haben ca. 80% aller aktuellen wissenschaftlichen Publikationen einen DOI. 98% dieser DOIs werden bei Crossref registriert. Die restlichen 2% verteilen sich auf die beiden Agenturen DataCite und mEDRA.
DataCite
Auch wenn der Fokus von DataCite bei Forschungsdaten liegt, haben einige Mitglieder von DataCite angefangen auch DOIs für primäre wissenschaftliche Publikationen wie Journals zu vergeben. Dies ist zwar nicht falsch, allerdings können mit dem auf Daten ausgerichteten Metadatenschema von DataCite einige Eigenheiten (z.B. Bibliografische Angaben oder auch Referenzen) nicht oder nur mit dem Verlust von Semantik ausgedrückt werden. Die Metadaten sind auch über eine eigene API ähnlich zu der von Crossref verfügbar:
- https://api.datacite.org/works/10.23675/sjlas.v31i1.57
- https://api.datacite.org/works/10.14763/2019.2.1418
Inzwischen empfehlen Crossref und DataCite gemeinsam, dass Zeitschriftenartikel, Konferenz papers oder Preprints besser bei Crossref registriert werden sollten.
mEDRA
Einige wenige Verlage die vom traditionellen Buchhandel herkommen, registrieren ihre DOIs via mEDRA. Die Metadaten können unter folgender REST API als XML aufgerufen werden.
http://www.medra.org/servlet/rest/metadata/10.2376/0300-4112-79-16
mEDRA bietet inzwischen auch eine Weiterleitung an Crossref an, so dass die Metadaten auch via Crossref-API erhältlich sind (z.B. 10.3238/ARZTEBL.2018.0008A)
Crosscite
Um die spezifischen Metadaten der verschiedenen DOI Agenturen zu erhalten, ist es unumgänglich über das jeweils spezifische Metadatenschema zu gehen.
Für einfachere Anwendungen, wie beispielsweise ein Zitat in einem bestimmten Zitierstil oder BibTeX zu erhalten, haben Crossref, DataCite und mEDRA zusammengespannt und bieten unter crosscite.org eine gemeinsame Abfrage und Ausgabe an.
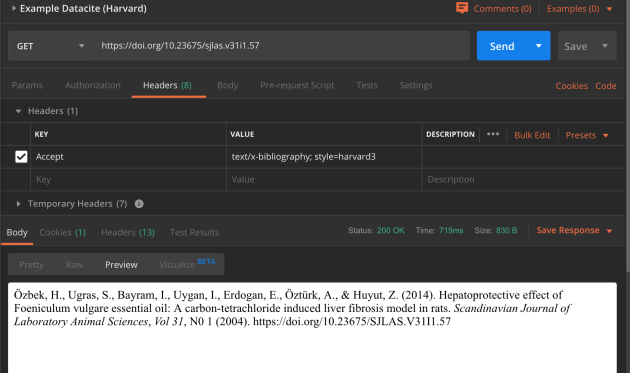
Zitation (Harvard) via DataCite 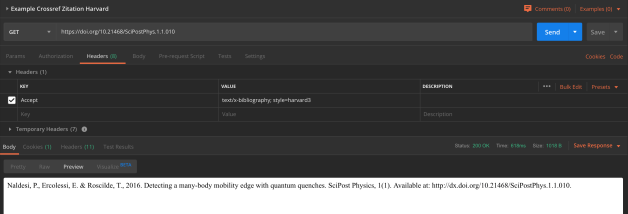
Zitation (Harvard) via Crossref 
Bibtex von Crossref 
CSL via DataCite 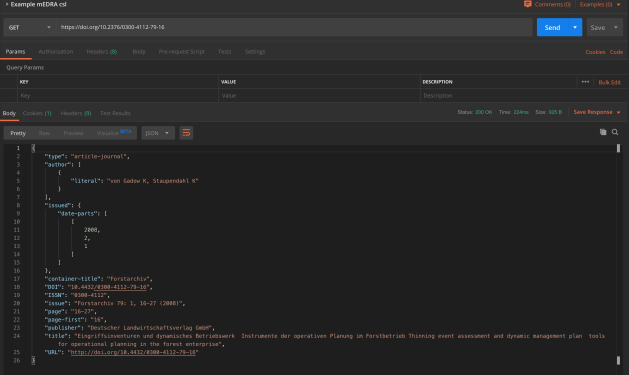
CSL via mEDRA
De facto Standard
Für primäre wissenschaftliche Publikationen (insbesondere Zeitschriftenartikel, Bücher und Buchkapitel) ist die Registrierung und das Abliefern von Metadaten bei Crossref inzwischen ein de facto Standard geworden. Die Vollständigkeit der Metadaten unterscheidet sich jedoch noch stark nach Verlag bzw. Herausgeber.
Vor kurzem hat Crossref ein Dashboard geschaffen, wo man für die über 12’000 Mitglieder sehen kann, wer welche Metadaten liefert.


Für Repositorienbetreiber stellt sich die Frage, über welche Agentur sie DOIs für ihre Publikationen und Forschungsdaten vergeben sollen. Die beschriebene Praxis, Datacite-DOIs trotz ungeeignetem Metadatenschema auch für Artikel u.ä. zu vergeben, rührt wohl daher, dass die Registrierung bisher kostenlos ist https://www.tib.eu/de/publizieren-archivieren/doi-service/informationen-fuer-interessenten/ Allerdings hat Datacite vor kurzem ein neues Mitgliedschaftsmodell inkl. Preisliste https://datacite.org/pricelist.html verkündet. Verglichen mit dem Preismodell von Crossref https://www.crossref.org/fees/ dürfte Datacite für viele Einrichtungen wohl teurer werden als Crossref. Bleibt zu hoffen, dass demnächst ein Modell entwickelt wird, bei dem die Einrichtungen sowohl Crossref- als auch Datacite-DOIs vergeben können, zu akzeptablen Preisen.
Pingback: DOIs und umfangreiche Metadaten bei Crossref | Archivalia
Schöne Übersicht zu den Metadaten. Allerdings zeigen unsere Analysen anhand eines Abgleichs von 10’000 Repository-Einträgen des Publikationsjahrs 2018 mit Crossref, dass die Abdeckung an Affiliationdaten sehr schwach ist (31%). Dazu ist Crossref zu sehr abhängig davon, ob die Verlage die Angaben liefern oder nicht. Datenbanken, die Papers systematisch exzerpieren, wie z.B. Scopus, verfügen über eine wesentlich höhere Abdeckung an präzis erschlossenen Affiliationsdaten (>98%), die zudem noch normalisiert vorliegen. Aber das hat bekanntlich seinen Preis. Ebenso haben wir festgestellt, dass Angaben zu Reihentiteln etc. in Crossref z.T. inkonsistent erfasst sind. Das Datenmodell von Crossref ist gut (z.T. aber ungenügend dokumentiert), aber die Datenlage ist noch eine Baustelle.
Sali Martin
Crossref hat gerade Änderungen im Schema bezüglich Affiliation vorgeschlagen, insbesondere um ROR zu integrieren: https://www.crossref.org/blog/proposed-schema-changes-have-your-say/
Wie du sagst ist die Qualität der Metadaten bei Crossref nur so gut wie Verlage diese auch liefern. Und sehr viele Verlage liefern sehr wenig. Ich bin hier dediziert der Meinung, dass diejenigen die das System mit Subskriptionen oder APCs bezahlen auch konkret hinschauen müssen und umfangreiche Metadaten von den Verlagen explizit verlangen müssen, weil nur dann Verlage sich die Mühe machen auch eine Best Practice zu erreichen.
Mir scheint hier ein zunehmend grössere Bewusstsein dafür zu entstehen: http://doi.org/10.1629/uksg.489
Da sehr viele Systeme die freie Daten von Crossref nutzen, wäre es sehr effektiv, die Qualität bei der Quelle zu verbessern, als letztlich dann in den nutzenden Systemen (Wos, Dimensions, Scopus, Lens, Repositories, EPMC, DOAB/OAPEN, DOAJ etc.).
Ich könnte mir auch gut vorstellen, dass Crossref in Zukunft auch eine Rückintegration von angereicherten Daten (aktuell siehe: https://doi.org/10.1007/978-3-030-11226-4_11) zulässt.